למידה רזה
02/02/2025

כולנו מתלהבים מטכנולוגיית "למידה עמוקה" [1] באינטליגנציה מלאכותית ובמיוחד ממודלי השפה הגדולים, המשמשים אפליקציות כמו ChatGPT. מאמרים פופולריים רבים נכתבים עליה ומציעים דרכים להשתמש בה ביעילות, ומעטים מדברים על מה שמסתתר מאחוריה: המוני חישובים מתמטיים מורכבים שמשתמשים בפרמטרים מספריים הקרויים משקלים. עקב מורכבות הנושא, נתמקד בתחום אחד: לטכנולוגיה יש עלות גבוהה (הנגזרת מגודל הזיכרון וכמות המערכות הנדרשות, מצריכת חשמל גדולה ומהצורך במערכות קירור מתקדמות) והחוקרים מחפשים דרכים להקטין אותה, בין השאר באמצעות הקטנת גדלי המשקלים, כפי שנסביר בהמשך. לאחרונה הוצגה טכנולוגיה חדישה בשם deepseek-r1, שגם היא נועדה להוריד עלויות, ונספר עליה בעתיד. הפוסט מוקדש לחובבי ביטים עם ידע בסיסי בחישובים נומריים, אבל גם מי שלא ייכנס לחישובים יוכל להבין את הרעיון הכללי.
פרסומת
השימוש בלמידה עמוקה נעשה בשני שלבים: השלב הראשון הוא שלב האימון, ובו מספקים למערכת הקרויה "רשת עצבית" נתונים רבים (בכלל זה ספרים, מאמרים ועוד), והיא לומדת לענות על שאלות בצורה חכמה. תהליך זה הוא יקר, ארוך ומבוצע לעיתים רחוקות. בסיומו הרשת מנפיקה כמות עצומה של מספרים הקרויים משקלים, שמייצגים את מה שלמדה. המשקלים הללו משמשים את הרשת בשלב השני, שלב היישום, שהוא השימוש היום-יומי במערכת, כמו למשל בשיחות עם ChatGPT. לרשת GPT4 המשמשת כיום את ChatGPT יש כ- 1.5 טריליון משקלים (תזכורת: טריליון = 10 בחזקת 12) שחושבו בתהליך האימון. אכן, כמות עצומה. אין פלא שהרשת חכמה!
כשאנו משוחחים עם ChatGPT בתצורה מתקדמת, האפליקציה משתמשת במשקלים הללו וב-24 אלף המילים האחרונות ששימשו אותנו בשיחה, כולל השאילתא (Prompt) הנוכחית, השאילתות הקודמות והתגובות הקודמות של האפליקציה. באמצעותן היא מחשבת מהי המילה הכדאית ביותר להציג על המסך בכל שלב, כדי שנחשוב שאנחנו מדברים עם גאונה. החישוב מורכב משלבים רבים וכולל מיליארדי הכפלות וחיבורים. המילים שנכנסות לרשת הופכות לוקטור (רשימה של מספרים), עליו מבצעים חישובים תוך שימוש במשקלים שנשמרו בשלב האימון. לבסוף מייצרים וקטור ארוך, לדוגמה בסדר גודל של 30 אלף איברים המייצגים את כל המילים במילון האנגלי, ובוחרים במילה עם הערך הגבוה ביותר, שזו המילה שהרשת החליטה שבהסתברות הגבוהה ביותר היא המילה הכי מתאימה להצגה על המסך.
פעולה בסיסית ברשת היא חישוב המכפלה הסקלרית בין וקטור זמני A שחושב בשלבים הקודמים ברשת ובין וקטור משקל W שחושב כאמור בשלב האימון. נניח שוקטור A ווקטור W מכילים כל אחד 64 איברים. המכפלה הסקלרית מוגדרת כהכפלת כל איבר ב-A באיבר המתאים לו ב-W, וסיכום 64 המכפלות. פעולה כזאת נעשית בשלבים שונים ברשת, עם גדלים וערכים שונים של וקטורי A ו-W:
A’ = A0*W0 + A1*W1 + … A63*W63
אפשר לתהות באיזו מידה משפיע דיוק החישוב על ביצועי הרשת? אולי אפשר להקטין אותו במקצת ולחסוך בחומרה? הרי החישוב של המילה הבאה להצגה הוא הסתברותי, אנחנו לא נשתמש ב-ChatGPT לחישוב מסלול של טיל בליסטי, וכולנו יודעים שגם בהכפלה בדיוק גבוה האפליקציה לעיתים הוזה ומייצרת שטויות במיץ עגבניות.
בחלק זה נתאר שיטה חדשה לשמירת המשקלים הצורכת פחות זיכרון ומקטינה את החומרה הנדרשת להכפלה, תוך פגיעה קטנה יחסית בדיוק החישוב. לפני כן, תזכורת קצרה ממתמטיקה תיכונית: כשמכפילים מספרים גדולים או קטנים מאוד, משתמשים בכתיב מדעי. למשל, בסימון הנהוג באקסל:
4E3 * 5E9 = (4*10^3)*(5*10^9) = 20*10^12 = 20E12 = 2E13
מספר המיוצג בכתיב מדעי שנקרא גם "נקודה צפה" (floating-point), למשל 2E13 שזה 2 כפול 10 בחזקת 13, בנוי מחלק הקרוי מנטיסה (בדוגמה: 2) ואקספוננט (בדוגמה: 13), שהוא המעריך של החזקה כאשר בסיס החזקה הוא 10. פעולת הכפל נעשית על ידי הכפלת המנטיסות, חיבור אקספוננטים, וארגון התוצאה לצורך תצוגה סטנדרטית.
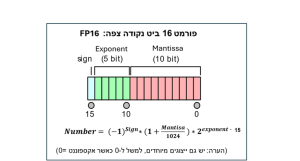
גם במחשבים נשמרים המספרים בצורה דומה, אולם בשיטה בינארית [2]. באפליקציות רגילות משתמשים בפורמט בן 32 ביטים ("סיביות") הקרוי FP32. באפליקציות בינה מלאכותית הפורמט המקובל נקרא FP16 (ראו איור להלן), ובו כל מספר נשמר באמצעות 16 ביטים: ביט אחד מציין את הסימן (חיובי או שלילי), 5 מוקדשים לאקספונט שהוא המעריך של החזקה כאשר בסיס החזקה הוא 2, ועשרה ביטים במנטיסה, כמו בדוגמה, הכפלת המספרים נעשית באמצעות הכפלת מנטיסות, חיבור אקספוננטים, וסידור התוצאה לצורך שמירה בפורמט סטנדרטי. הבעיה היא גודל הזיכרון המוקצה לכל משקל (16 ביטים) וגודל החומרה הנדרשת להכפלת המנטיסות.
לפני כשנה הוציא פורום משותף של מומחים בחברות טכנולוגיה מובילות (אנבידיה, AMD, אינטל, מטא וקוואלקום) מסמך הגדרה של סטנדרט חדש (MXFP) לייצוג מספרים בפורמט נקודה צפה [3] המאפשר ייצוג באמצעות 8 ביטים, 6 ביטים, או אפילו 4 ביטים! בייצוג 4 ביטים הקרוי FP4 ניתן לייצג רק 8 ערכים חיוביים ו-8 שליליים. אז כיצד ניתן להשתמש במספר כה קטן של ערכים אפשריים עבור כל משקל ברשת ועדיין לקבל ביצועים טובים?
האמת היא שרימינו: הייצוג האמיתי של מספר שנשמר בפורמט FP4 הוא 4 ביטים, אבל בצמוד אליו יש מספר נוסף שנקרא לו S (קיצור של Scale) המכיל 8 ביטים, הערך האמיתי של המשקל בפורמט MXFP4 הוא המכפלה של FP4 עם 2 בחזקת S…
MXFP4 = FP4 *(2^S)
אם כך, הייצוג כולל 12 ביטים (4+8) ולא 4, אז מה הקסם?
כאן מגיע הטריק: מחקרים הראו שאיברים סמוכים בווקטורי המשקלים הם בדרך כלל די קרובים בערכם, ולא משתנים בקפיצות גדולות. לפיכך, ניתן לחשב ולשמור ערך יחיד של S עבור כל קבוצה של 32 משקלים עוקבים, ערך המחושב לפי האיבר המקסימלי בקבוצה, בלי לאבד יותר מדי דיוק. במקום לקרוא מהזיכרון 32 ערכים של 16 ביטים (FP16), ניתן לקרוא בשיטת MXFP ערך אחד של S (המכיל 8 ביטים) ולאחריו 32 ערכים עם 4 ביטים. חיסכון גדול!
מה בדבר חיסכון בחישובים? גם כאן יש טריק. כזכור החישוב הבסיסי שנעשה במערכות בינה מלאכותית הוא הכפלת וקטור משקלים W בווקטור זמני A. לפי חוק הפילוג במתמטיקה, כיוון של-32 משקלים יש איבר מכפיל זהה, ניתן "להוציא אותו מהסוגריים", לחשב קודם את סכום המכפלות תוך שימוש ביחידת חומרה פשוטה להכפלת מספר בפורמט FP4, ורק כעבור 32 פעולות כאלו להכפיל בשתיים בחזקת S ולחבר. מגניב!
פורמט MXFP הוא חדש. בדיקות ראשוניות הראו שיש לו פוטנציאל טוב [3], אבל צריך לחכות למוצרים אמיתיים. ואם אתם חושבים ששימוש ב-4 ביטים בלבד למשקלים הוא מוגזם - חשבו שוב. מחקרים חדשים מראים שניתן לחסוך עוד על ידי שימוש ברשתות הנקראות טרנריות [4, 5], שבהן המשקלים מיוצגים על ידי 2 ביטים המכילים את שלשת המספרים 1, 0, 1- בלבד, וההכפלה נהפכת לחיבור או לחיסור. יש אפילו מחקרים על רשתות בינאריות [6] המשתמשות בביט אחד המייצג את שני המספרים 1 או 1-. שימוש במכפלים קטנים יכול לאפשר פיתוח חומרה ייעודית המשלבת למשל חישובים בתוך זיכרון.
כולנו מקווים שהמומחים ימצאו דרכים להקטין את העלות של למידה עמוקה וכן יאפשרו שימוש במודלי שפה גדולים גם במחשבים ניידים ואפילו בטלפונים.
עריכה: שיר רוזנבלום-מן
מקורות
[2] על ייצוג בינארי
[4] תוצאות ראשונות על MXFP (מאמר)
[7] רשתות בינריות

מהנדס מחשבים, חוקר ויזם בתחום החינוך המתמטי.

מהנדסת ביוטכנולוגיה, כיום מנהלת את מערך השיווק והאופרציה בחברת "אידיאה ביו-מדיקל" המתמחה במיקרוסקופיה אוטומטית למחקר ביולוגי.